Ray解读:从论文看架构
1. 简介
人类的想象力是无限的,人类产生的数据也是无限的?当数据不得不突破单机处理的极限的时候,分布式应用就应运而生了。同理,挖掘数据潜力的机器学习算法也会有这样的瓶颈。目前来看,分布式ML主要构建如下几个平台:
- TF,torch,MXNet 比较常用单机框架,实际上也可以扩展到分布式
- 集群的情况:SPARK MLlib,Alink(基于Flink)基于一些现有的分布式框架做的
- 多GPU的场景:Horovod ,Ring allreduce 有钱就是好啊(笑)
Ray是一种新的分布式计算框架,是诞生了spark的AMPLib的作品,下面我们简单介绍ray的系统框架,和运行机制。
2. 系统框架简介
In this paper, we propose Ray, a general-purpose cluster-computing framework that enables simulation, training, and serving for RL applications. The requirements of these workloads range from lightweight and stateless computations, such as for simulation, to longrunning and stateful computations, such as for training.
Ray的定位是分布式通用计算框架,可以提供耗时较久的训练计算,同样也支持对耗时要求严格的推理过程。Ray主要包括两部分:
- 分布式的任务调度器:bottom-up调度策略
- 元数据存储GCS:一个中心化的数据存储
在这两个基础框架之上,ray的应用程层(application)使用传统的driver-worker模式进行组织。
- driver:运行用户程序的进程
- worker:执行指定的远程任务(remote function),这个任务可以来自driver,也可以来自其他worker。woker会自动启动,同时worker是无状态的
- actor:可以认为是一个有状态的worker 从物理层面上,每个集群节点(node)除了worker,actor进程之外,还存在名为raylet的组件,这个组件承载该节点和其他节点通信以及保存数据的功能,raylet实际上是以下两个组建的封装
- local scheduler:本地调度器,两级调度策略的第一级
- obj store:本地存储器,用于存储task输入输出结果
2.1 Global Control Store (GCS)
GCS系统维护整个系统的状态,他的核心是是KV存储和基于KV存储的订阅发布机制。 ● 容错:大部分容错机制,一般只利用一个节点去保存历史信息,但是细粒度的情况不太实用,Ray将历史信息的保存机制和依赖的其他组件之间解耦出来,使它可以单独扩展 ● 低延迟:为了尽可能的减少延迟,ray将人物的数据对象和调度器分开,相当于这些对象都保存在GCS上,不需要调度自己维护。这样每个组件都将数据存在一个地方,减少了复杂度,也对外围的prof等功能的开发提供了便利。但是这样的设计不会产生大量的IO payload? GCS自己也是分布式的,可以等同一个分布式的redis集群+一个统一入口
2.2 调度器
动态执行的前提下,一般的全局调度器就没办法只调度一次了。Ray的调度器有两部分组成,一个是全局调度,另一个是每个节点上的本地调度。本地调度器首先尝试在本地执行调度,如果无法在本地完成调度的任务,就交由远程的全局调度器。也就是说在一个异构的计算集群(CPU,GPU),也可以执行同构的任务。
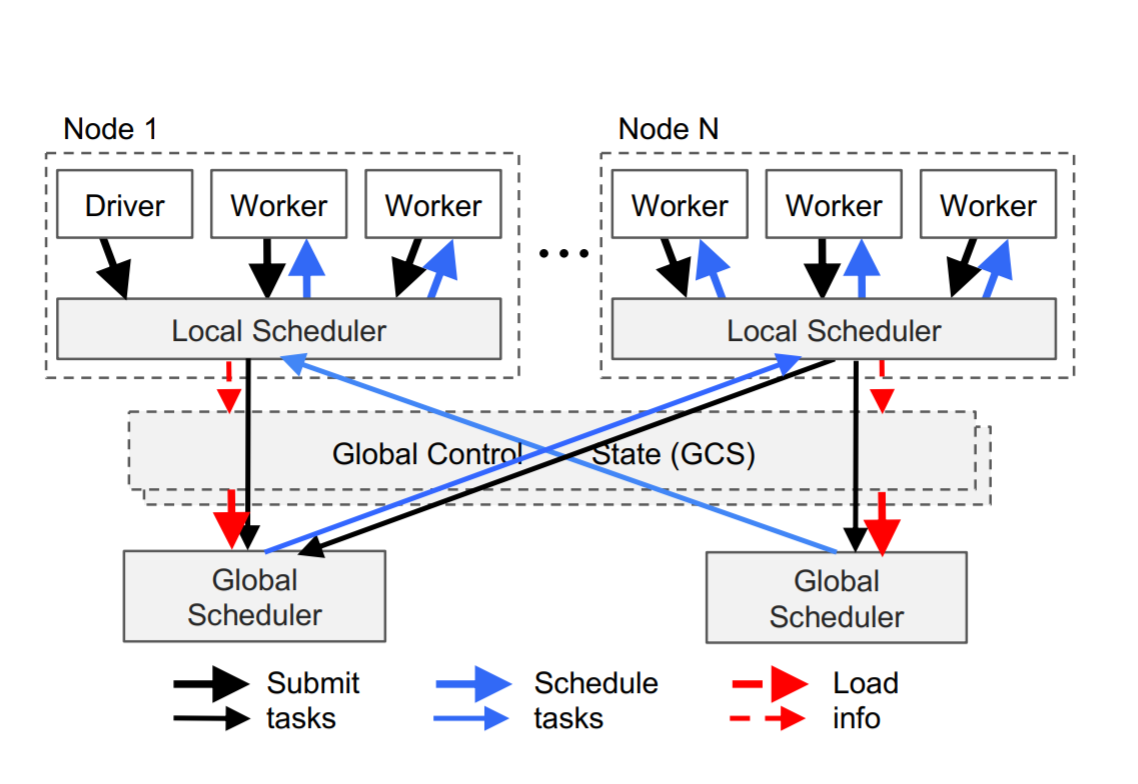 上图为Ray一次调度的情况,首先driver提交任务到本地调度器,本地调度器将任务交给本地的worker,然后将完成不了的任务提交到全局调度器,全局调度器会根据每个节点的资源和预期等待时间,决策任务的调度去向。预期的的调度时间可以根据任务在队列中的时间,任务的网络IO耗时来决定。这些信息可以根据心跳机制来获取。
当全局调度器自己成为瓶颈之后,我们可以根据GCS的中的信息来快速的横向扩展全局调度器
上图为Ray一次调度的情况,首先driver提交任务到本地调度器,本地调度器将任务交给本地的worker,然后将完成不了的任务提交到全局调度器,全局调度器会根据每个节点的资源和预期等待时间,决策任务的调度去向。预期的的调度时间可以根据任务在队列中的时间,任务的网络IO耗时来决定。这些信息可以根据心跳机制来获取。
当全局调度器自己成为瓶颈之后,我们可以根据GCS的中的信息来快速的横向扩展全局调度器2.3 对象存储
Ray还实现了一个基于内存的对象存储,同节点的worker可以通过shared mem机制来获取数据。数据的格式为Apach Arrow 。每个任务的输入,输出都写入本地内存中,这样做的目的是提供一种缓存机制,并且减少了每个task的执行时间。内存不够时,我们还可以用LRU机制将部分数据写入磁盘。 当node出现宕机时,ray通过GCS中的历史信息,重新执行这些任务,进行对象的重现。 这种对象存储不支持的分布式的对象,可以在应用层来获取这些大对象的分片。
3. 小结
本篇简单介绍了ray的底层架构,
- Ray主要是一种分布式的计算框架,通过全局存储机制,两段式的调度来实现动/静台的执行计算,也可以很方便的进行扩展,并且在设计中考虑了容错和低延时
- ray的全局对象存储减少了细粒度任务的拉取数据的耗时,并且提供了全局的历史信息保存。同时将调度和数据解耦,使他们可以单独扩展
Ray涉及运行的流程和一些细节,之后会有系列文章,来介绍更多的细节和例子。
参考资料
Ray: A Distributed Framework for Emerging AI Applications https://arxiv.org/pdf/1712.05889.pdf
https://cloud.tencent.com/developer/news/685491