1. 前言:
上一篇,笔者简单介绍了ray的系统框架。系统层面上,ray主要通过中心化的(centrallized)存储,控制一体的中心服务,和两级调度器,来实现高效的分布式计算。本片我们换个视角,从任务和编程模型的角度,解析ray背后的运行机制。
2. Ray编程模型:
Ray中的任务基本单元为Task,在Task构成的计算图上,又提供Actor机制,支持有状态计算。
- Tasks:task代表一组被远程执行的函数,这种函数在worker上执行,他们的结果是异步的,也就是在执行后悔先生一个future,然后通过get来获取具体的结果。每个这样的remote function,通过输出输入构成依赖关系。同时会根据这些依赖关系进行容错。
- Actor:Actor是一种有状态的计算任务,意味着他可以内部保存一些任务执行的状态。Actor中的函数和构成task的remote函数相同,但是不同之处他们的执行环境是有状态的。
接下来是一个Task和Actor的对比
| Task | Actor | |
|---|---|---|
| 负载均衡粒度 | 细粒度 | 粗粒度 |
| 本地缓存 | 支持 | 支持力度弱 |
| 任务更新开销 | 低 | 高 |
| 容错效率 | 高(血缘信息) | 低(checkpoint) |
上面的表格总结两种计算单元的不同,相比于task的轻量级,Actor更适合用于比较复杂的任务,比如Parameter Server或者基于GPU的迭代计算。 二者在具体代码中,task一般是一个py函数,而actor是一个py类
3. 运行流程
我们通过一个简单的a+b例子来展示Ray运行流程。
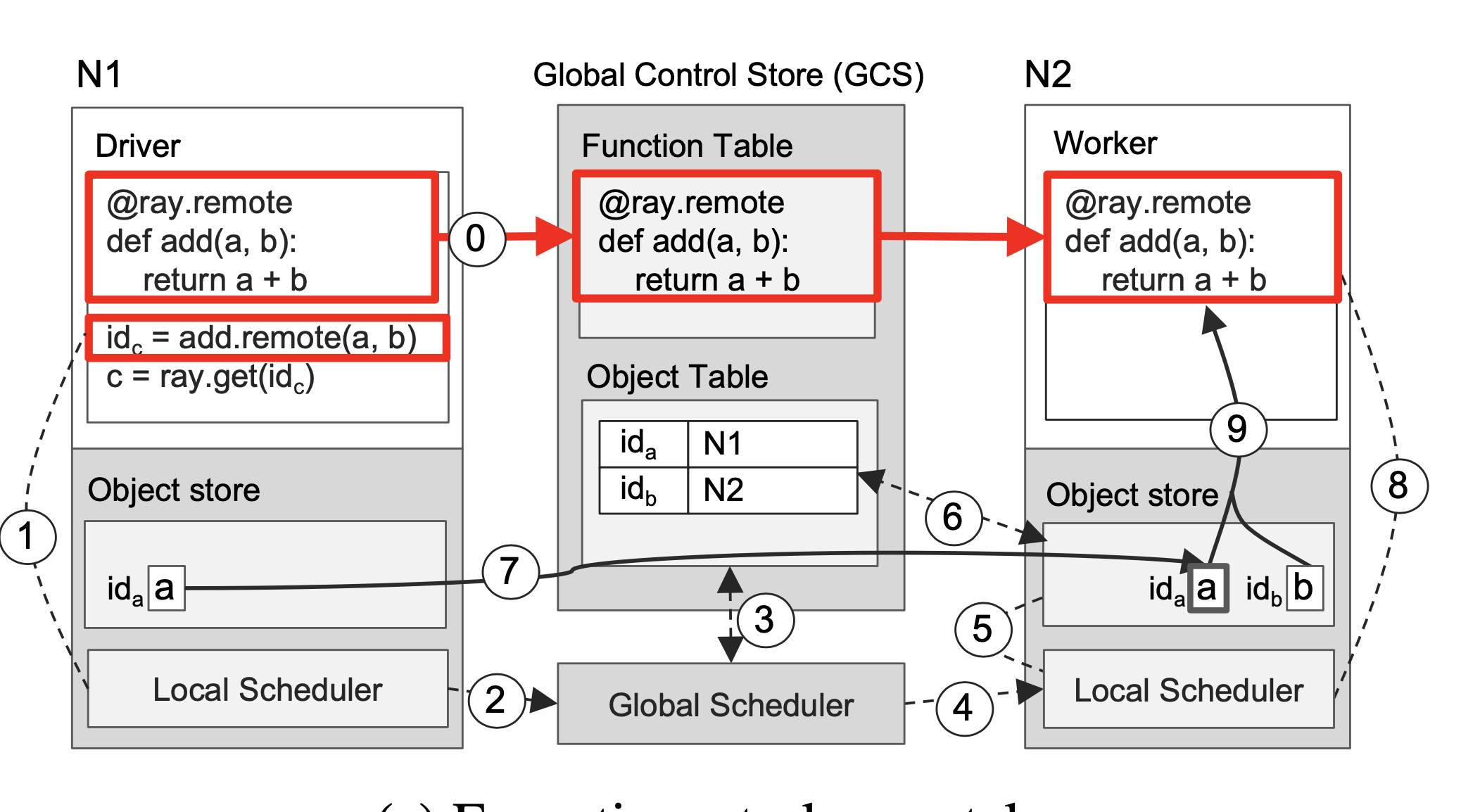
运行阶段
在执行初始化时,在GCS上注册的远程函数会被分发到每个worker上,我们设定这两个对象分别在两个node上,当driver触发了这个函数。driver会向本地的调度器发起调度请求,本地的调度器向全局调度器发起调度请求,也可以不请求,直接在本地进行执行。
如果在全局调度器进行调度,它选择在N2节点上执行这个task,N2节点上的本地调度收到调度信息后,会查看本地的对象存储中是不是存在task的两个输入对象,此时objA并不在N2节点上,他需要从GCS中的object table(对象-存储位置表)拿到objA的地址,并且复制到N2上,这个时候两个输入参数都全了,本地调度器可以在N2的worker上执行这个函数。
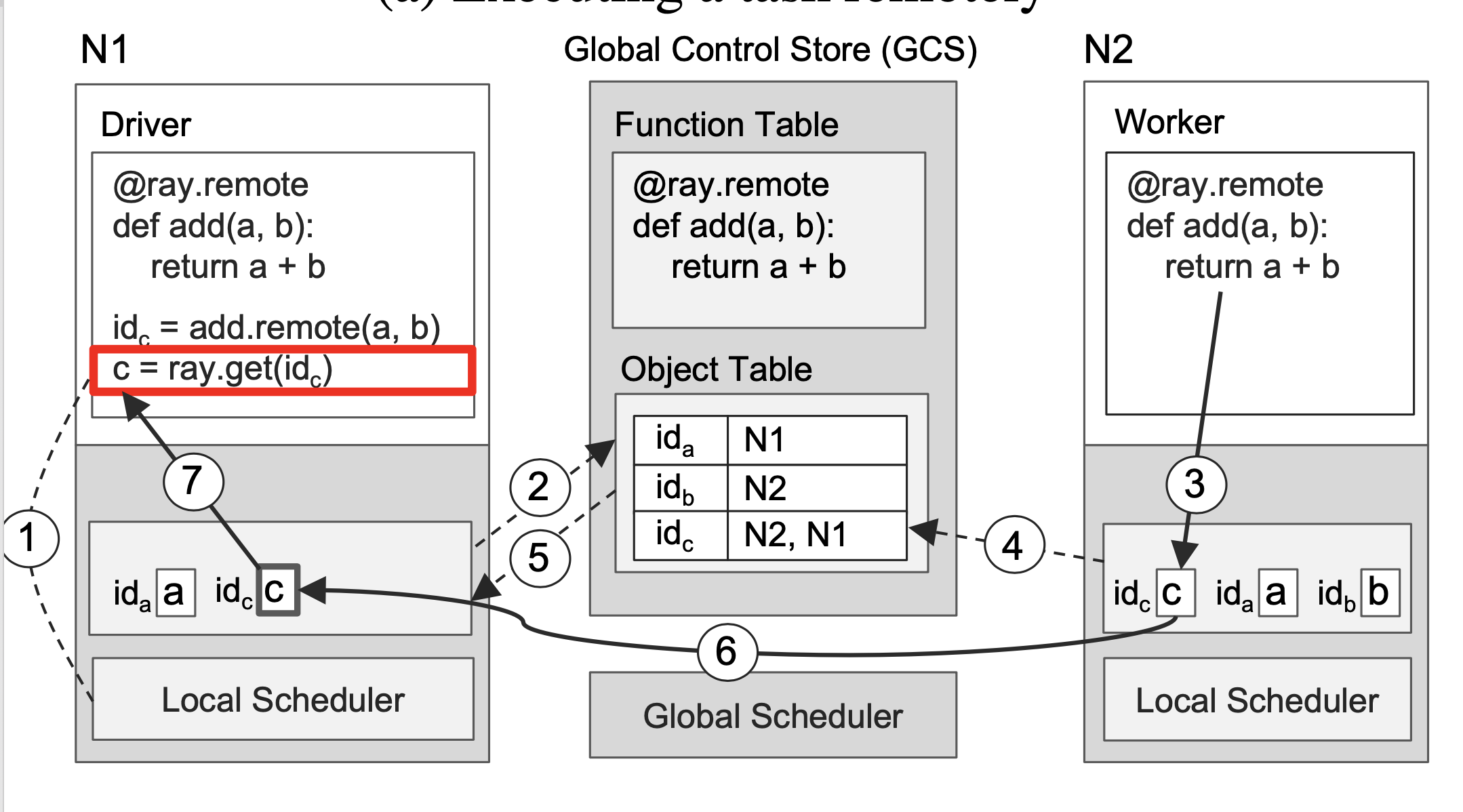
获取结果
当我们在N1调用ray.get(id_c)时, N1的本地调度器会先从查看本地是否存在这个id对应的对象,如果没有这个对象,就会想全局调度器查询该对象的位置,此时该对象如果没有被创建,也就是说N2还在执行这个函数,因此在objtable中没有这个对象。N1会先注册一个回调函数,等到N2执行完成后,会将结果对象c存储在本地种,并且在GCS中注册这个对象,当对象被注册的时候,上文说到的N1创建的回调函数会被触发,此时N1会从N2将结果复制过来,并将该结果返回到get的触发的task。
整个过程包括了很多次的RPC,但是在大多数情况下,全局调度的触发次数不会很多,同时和GCS相关的请求也会被缓存,整体下来网络耗时并不会很高。
容错机制
一般的,task会产生两种错误
- 应用层:task自己产生了error,但是worker进程还没有被杀死,这种情况下,该任务不会被重试
- 系统层:worker进程挂了(比如segment fault),或者本地的raylet等系统组件挂掉了,这种情况下该任务会被重试若干次
4.小结
解析运行流程,我们可以发现,ray在运行时,总是先尝试在本地寻找对应的资源,并且在将资源复制到本地之前,都不会立刻执行对应的任务。整个流程就是本地-全局-本地的一个流程。由于论文中的一些例子都比较就,下一篇架构解析,我们会从最新版本的文档和白皮书入手。