1. 前言:
本片我们来解读ray白皮书中的对象存储管理的部分,在本篇,我们需要关注两个问题:
- object是如何创建,销毁的?
- object和内存的关系? 先来解释一些ray中对象的概念:ray中的对象可以通过一个task的返回或者ray.put方法创建,一旦被创建,这个对象就变得不可变。每次创建的时候,都会创建这个对象的引用,每个worker都可以通过这个对象的对象引用(objectRef)来获取这个对象的值。
另外一个和对象密不可分的概念是所有权(Ownership):创建对象或者说对象引用的进程,需要对这个对象进行取值。这里化用了C++里面指针地址和指针指向值的概念,举个例子。有一个taskA需要另一个taskB的返回值,这个返回值目前只是一个引用,所以需要根据ownership来让TaskB返回这个结果.有关引用的更多信息。通过对象的引用,获取对象的值的过程,我们称之为对象解析(Object resulotion)我们会在引用计数这一部分细讲。
2. object的生命周期

创建和引用
Ray中对象是通过worker,或者通过ray.put进行的,执行这个操作的worker或者driver进程就是这个对象的owner。只要owner保持运行,那么这个对象就一定可以被解析。但是如果owner已经挂掉了,针对这个对象的解析就会失败。因为解析的过程实际上就是一个懒加载的问题。
每个worker都会保存自己所有对象的ref,这种ref和指针类似,都具有引用计数,这种引用计数的规则如下:
- 传递给一个task的参数中,包含一个ref(包括一个对象中含有ref的情况,比如一个objref的list),计数会增加
- 返回的对象中,含有另一个对象,引用计数也会增加
保存和解析
每个对象除了在owner的内存中保存外,还可以保存在单个node的共享内存中,或者分布式的保存在不同的节点上。这是通过Apache Arrow实现的
当我们调用ray.get或者将一个ref传给一个task的时候会触发针对这个ref的解析,当这个对象比较小的时候,这个对象会直接放入owner进程内部的内存中,如果是分布式的存储,则需要进行几次rpc才能解析,这里在接下在会单独列出。
错误处理
当一个对象在解析是出现了错误,那么这个错误会被直接抛出,不会让进程挂起,如果是存储在分布式内存上的对象,如果他的全部分片都丢失了,同样会触发错误。Ray可以通过重建机制来恢复丢失的对象
3.对象解析
对象引用:
一个引用本质上是一个字符串,由两部分组成:
- 20个字节长度的Id:创建这个对象的task的ID + 这个task创建对象的个数
- 对象owner(一个worker)的地址:worker的id+worker在的ip,端口,+raylet的ID
这里的ref组成,使得在整个系统都可以通过这个Id,唯一标识一个对象。而且本身保存的信息,也可以让对象加载的速度变快,比如最后的raylet的地址,使得其他raylet拿到这个ref之后,就不需要向GCS请求对象地址了
存储原则:
在提交ray task时,每个task依赖的参数都通过引用的方式进行解析调用。这里会有一个分别讨论。
- 当一个对象比较小的时候,那么这个对象会被直接存储在内存里面
- 当一个对象比较大的时,通过arrow存储在分布式存储上,只留下一个占位符,通过它来获取这个对象
ray选择根据对象大小大小分别处理,而不是像spark一样先读取所有的数据到内存(会经常性的导致内存不足),也不是激进的让所有的对象都通过arrow分布式存储。
优势和劣势
首先小对象存储在内存中,在解析时无需进行网络传输,加快这个对象的解析速度。但当一个对象被很多个worker同时引用时,就会在整体内存中被复制很多次。 相反的,想要获取一个远程的对象,至少需要请求一次本地的分布式内存系统,当worker所i在的机器上没有完整的数据时,RPC的数量不可避免的会增加。但是多个worker将能够同时访问一个内存系统,这样一个对象被复制多次的问题就不存在了。如果这个对象在被序列化的时候支持0拷贝,那么解析的速度将进一步提升。
解析流程:
解析远程对象的流程如下:
- 当每个对象不在本地的共享存储中,那么解析这个对象的持有者会向raylet请求这个对象的内容
- raylet会向存有这个对象的其他部分的raylet请求拉取这个对象,这个对象的地址会被存储在本地
4. 内存管理
对于task执行产生的结果对象,如果对象比较小,那么该对象会先保存在worker内存中,但是比较大的对象,就会被放到本地共享内存。
这里提到一个概念:第一副本,指对象被第一次创建时,复制到共享内存的那个副本,在其他节点需要这个对象时,也会复制其一份到自己的共享内存中。除了第一副本,其他的内存副本都有可能被LRU机制淘汰掉,以节约内存。
如果第一副本失效了,那么这个对象的owner会指定一个有效的副本作为第一副本
内存回收
一个对象的引用计数如果变成0了,那么该对象的内存将会被自动回收。小的对象会被直接delete,比较大的对象会异步删除,防止占用其他进程的时间。
以下几种情况,会使得一个对象存在于本地内存
|场景 |描述| |—–|—–| |ray.get| ray.get或者ray.wait请求的对象会被保存到本地内存,当这个请求结束,并且这个对象被python回收之后,这段内存就会被释放| | ray.put |ray.put上传的对象,当引用计数为0时被回收| | task 返回值 |当一个task结束时,他的返回时会被先保存,同样遵循引用计数规则,或者,这个对象可能被被溢写了,此时也不会在内存中了| | 排队task入参 |ray会对还等待执行的task,先获取其参数,当任务运行开始之后,就会被释放| | 过去任务的依赖| 一个完成了的task的依赖对象,可能还没有被回收|
内存溢出处理:
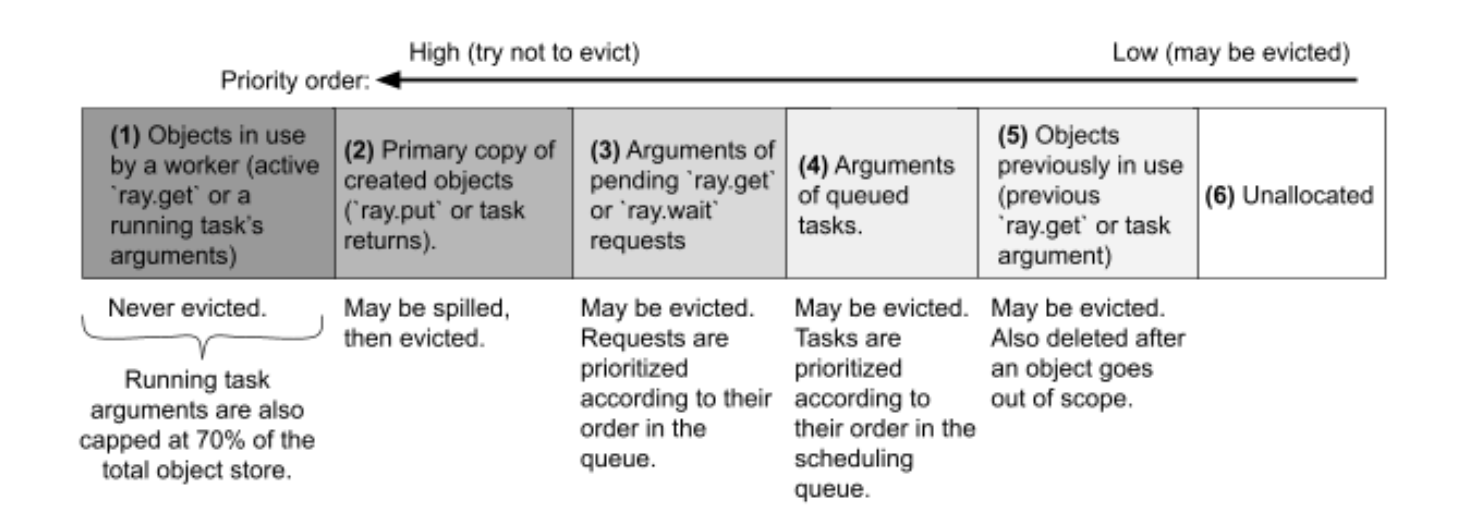 上图展示了针对对象来源决定的淘汰的顺序,从高到低,最先被淘汰的对象是已经完成task的入参对象,一般不会淘汰的是ray.get获取的对象
上图展示了针对对象来源决定的淘汰的顺序,从高到低,最先被淘汰的对象是已经完成task的入参对象,一般不会淘汰的是ray.get获取的对象
当对象创建时,内存不够,就会导致LRU的淘汰机制。但即使如此也有可能没有内存来创建新对象。这代表ray集群申请的资源不能满足应用所需的内存。
在 ray1.2中会触发内存溢写,如果内存不足的情况发生,那么ray可能会将对象的第一副本溢写到磁盘上,释放出他们占有的内存,如果没有开启溢写,此时会报错。
但如果ray.get获取的对象太多了呢?此时即使开启了溢写,内存释放出来的大小还有可能超过内存限制,同样会抛出错误。为了能够减少这种情况,ray限制了一个task可以获取的参数内存大小上线,默认为70%。这样可以保证至少30%的空间可以被剩余的task利用。尽管如此,ray仍旧无法保证ray.get会不会抛出异常。在当前版本,内存溢写仍在开发中。
5.小结:
简单来说ray对object的生命周期有几大特点:
- 尽可能利用本地存储
- 减少远程对象在传输网络消耗
- 通过溢写,回收机制尽可能的维护整体内存占用量
还有溢写比较大的点,回收机制,溢写机制,引用计数,这些都可以单拿出来仔细看看