1. BigDL简介:
BigDL是Intel开源的基于Spark,Ray深度学习框架。BigDL在1,0版本后,迁移到了Analytics Zoo这个项目下,目前看官方又要重新将重点迁移到BigDL的2.0版本上,BigDL的2.0版本整合了BigDL 1.0 和 Analytics Zoo中的能力,提供如下的能力
- DLlib:spark上的深度学习框架,也就是原本的BigDL1.0
- Orca:整合了PyTorch和Tensorflow两个框架,使得这些框架开发的模型可在分布式集群下进行训练,预测
- Chronos:时序分析库
- PPML:隐私计算相关库(开发中)
- 集群推理服务:分布式实时模型预测
笔者感觉,目前Orca和DLlib是工业场景下最重要的两个应用了,其他的分布式深度学习方案,比如Horovord,Tensorflow On Spark的环境配置相当的麻烦,BigDL仅需一个conda环境就可以运行。同时大部分的特征工程能力还是由spark提供,而BigDL内部也是基于Spark进行开发的,非常适合与现有的Spark任务进行整合
本篇会介绍如何如何进行Tensorflow模型进行分布式训练
2. BigDL在Yarn Cluster的运行流程
## 1. 首先打包一个Python env
官方推荐使用conda创建一个包含bigdl的env
1
2
conda create -n env python=3.7
conda activate env
接下来安装必要的包
1
2
pip install bigdl-dllib bigdl-orca[ray]
pip install tensorflow
Tensorflow的2.0版本,BigDL选择了使用Ray作为底层框架,如果不想使用Ray,可以安装下面的包
1
pip install bigdl-orca
安装好必要的库之后,需要对环境进行打包
1
conda pack -o environment.tar.gz
这样的打包体积比较大,很可能会导致提交任务时比较慢,但是出错的概率会少很多
## 2. 编写一个测试任务
在BigDL上使用TensorFlow进行开发的过程与在本地进行差不多,下面简单写个例子来做说明
演示的Tensoflow版本为1.15
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
from zoo.orca.learn.tf.estimator import Estimator
import tensorflow as tf
from zoo.tfpark.tfnet import TFNet
from zoo.tfpark.tf_dataset import TFDataset
# 初始化环境
init_orca_context(cluster_mode="spark-submit")
def model_creator():
import tensorflow as tf
model = tf.keras.Sequential(
[
tf.keras.Input(shape=(4,)),
tf.keras.layers.Dense(10, activation='tanh'),
tf.keras.layers.Dense(20, activation='tanh'),
tf.keras.layers.Dense(3, activation='softmax')
]
)
model.compile(optimizer=tf.keras.optimizers.RMSprop(),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
return model
model = model_creator()
# 转换
est = Estimator.from_keras(keras_model=model)
# 和keras差不多的方式
est.fit(data=df,
batch_size=8,
epochs=4,
feature_cols=['features'], #可以直接使用SparkDataFrame做训练数据
label_cols=['label'])
est.save_keras_model("xxx")
stop_orca_context()
BigDL1.0版本的tensorflow训练实现原理,实际上是做了BigDL原生API和Tensorflow的KerasAPI做了映射,然后直接使用spark进行分布式训练,这种方法最大的优点是稳定,非原生的实现方式是在Yarn上跑Ray,这个区别接下来会简单讨论下
保存好代码后,就可以提交到集群上了
## 3. 提交任务的配置
通过Yarn提交任务时,需要将参数archives设置为该压缩包的地址,线上执行pyspark任务时会使用该环境运行python代码。确定好安装好的package后,使用如下指令提交
1
2
3
4
5
6
7
8
9
10
spark-submit-with-dllib \
--conf spark.yarn.appMasterEnv.PYSPARK_PYTHON=environment/bin/python \
--conf spark.executorEnv.PYSPARK_PYTHON=environment/bin/python \
--master yarn-cluster \
--executor-memory 10g \
--driver-memory 10g \
--executor-cores 8 \
--num-executors 2 \
--archives environment.tar.gz#environment \
script.py
其中num-executors 这个参数是必须的,BigDL需要固定参数的excutor数量来进行任务分配,运行后会看到训练的相关信息
3. Spark On Ray
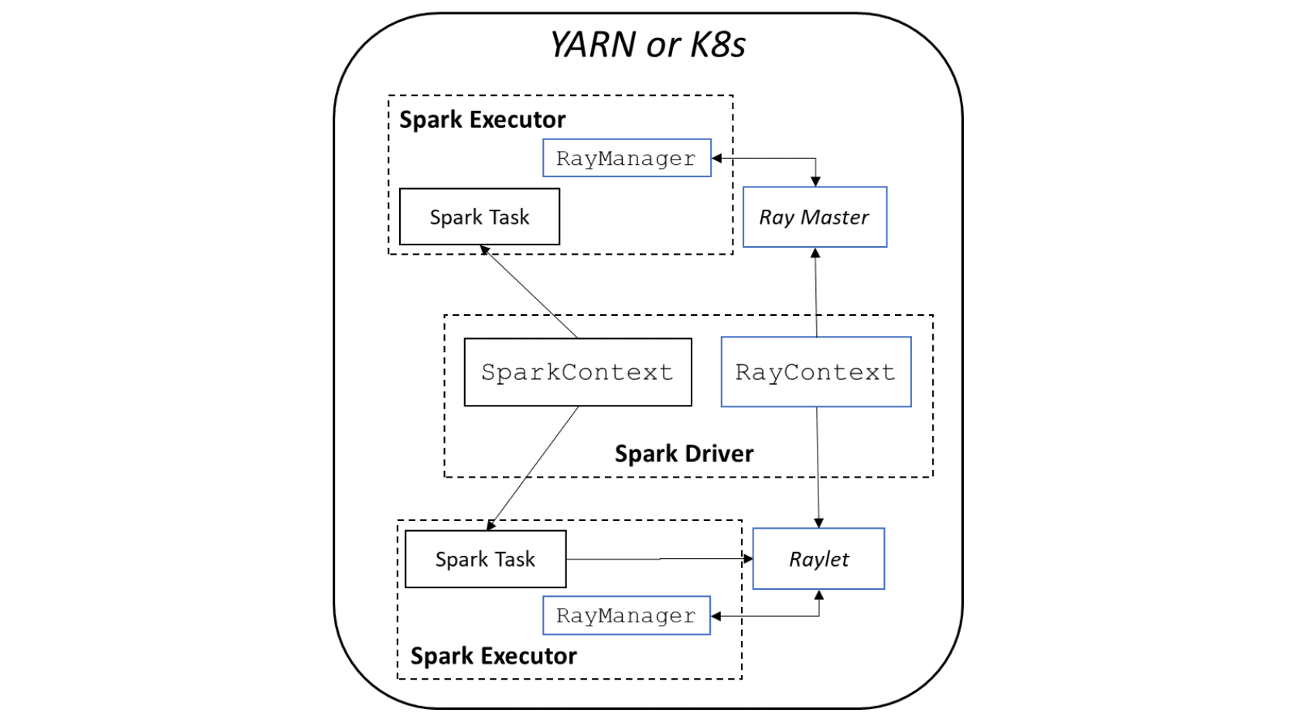 BigDL使用SparkOnRay的方式,直接在Ray上进行Tensorflow,PyTorch训练,数据由Spark进行分片。这套解决方案的好处就是以后Tensorflow,PyTorch有新的变更,那么BigDL是不需要做任何变更的。
BigDL使用SparkOnRay的方式,直接在Ray上进行Tensorflow,PyTorch训练,数据由Spark进行分片。这套解决方案的好处就是以后Tensorflow,PyTorch有新的变更,那么BigDL是不需要做任何变更的。
BigDL在Spark环境上又组建了一套Ray集群,Ray集群方案一般来说需要一个Redis服务做GCS,也就是说再YARN这种非隔离环境上,启动Ray的Driver和一套Redis,如果YARN集群不够稳定,出现几个Node挂掉,或者redis挂掉的情况。总而言之,实际使用起来问题很多,整体的成功率还是没办法保证的。实际上如果无法保证训练的稳定性,那么还不直接从hdfs拉取数据,然后在多机多卡环境上训练。
Spark目前来看是分布式场景下无可替代的组件了,后起之秀Ray想要完全替代Spark,还有很长的路要走
4. 参考资料
https://medium.com/swlh/seamlessly-scaling-ai-for-distributed-big-data-5b589ead2434
https://bigdl-project.github.io/master/