1. 前言
MIT的6.824课程:分布式系统,旨在传授学生分布式系统的基本原理:并行计算,任务调度,容错等等,是一门非常经典的好课,除了课程本身质量意外,他的lab(大作业),也是非常的具有实操性。本片文章将详细介绍这门课的第一个LAB:MAPREDUCE,并给出一个自己的version,供大家参考
2. mapreduce 介绍
大数据时代离不开的三驾马车:HDFS(分布式文件系统),MapReduce(分布式计算框架),Hive,是大多数人接触大数据处理和分布式系统时,一定绕不开的三个重要的组件。
mapReduce出现的场景如下:首先随着网络爬取结果,日志文件等等越来越大,单台机器处理海量数据已经时不可接受的效率地下了,MapRed旨在提供一个并行化计算框架,让这些数据的结算流程可以在多台机器之间并行,并且可以容错。
mapred的流程,顾名思义,主要由map,reduce两部分组成。map部分负责处理每个数据分片的初步计算,将他们变成kv对的形式,并将这些结果写入分布式系统(或者说磁盘)。reduce则读取上一步的中间结果,这一过程也称为shuffle,并将这个kv对按照key相同进行聚合,最后同样保存结果。
map和reduce存在多个时,每个map任务一般情况下可以认为负责一个或者多个数据分片,拿到中间结果之后,下一步会将所有的key拆分成reduce数量的组,每个reduce任务只负责聚合自己负责的那一部分。
我们用一个经典的例子(wordcount)详细介绍计算流程
- 首先:假设所有的输入文件已经被切分了
- Map过程的任务就是将这些且数据分片中的文本片段切分出若干个单词,每个单词形成一个kv对:(word,1),并将这些中间结果写入文件系统中。
- Reduce任务会拉取上一步的任务,然后将对应的key的结果进行聚合,然后写入到最终的结果
简单用代码描述一下:
1
2
3
4
5
6
7
8
9
// map 函数 输入的value是文本内容,key不需要输入
func map(key:string,value:String) :
content = []
for word in value.split:
content.append({word:1})
write_content(content)
// values 是一个数组,上一个数组的array
func reduce(key:string,values:array) :
write_result(({key:len(values)}))
任务设计好之后,如何让这些任务分布式的运行起来呢?首先我们定义一个计算的框架,这个框架由两部分组成:master,worker
- master节点负责接受任务,按照先后顺序,将map,reduce任务下发到worker
- worker节点负责接受任务,并且负责具体人无法的执行,执行结束之后将任务回报给maser节点
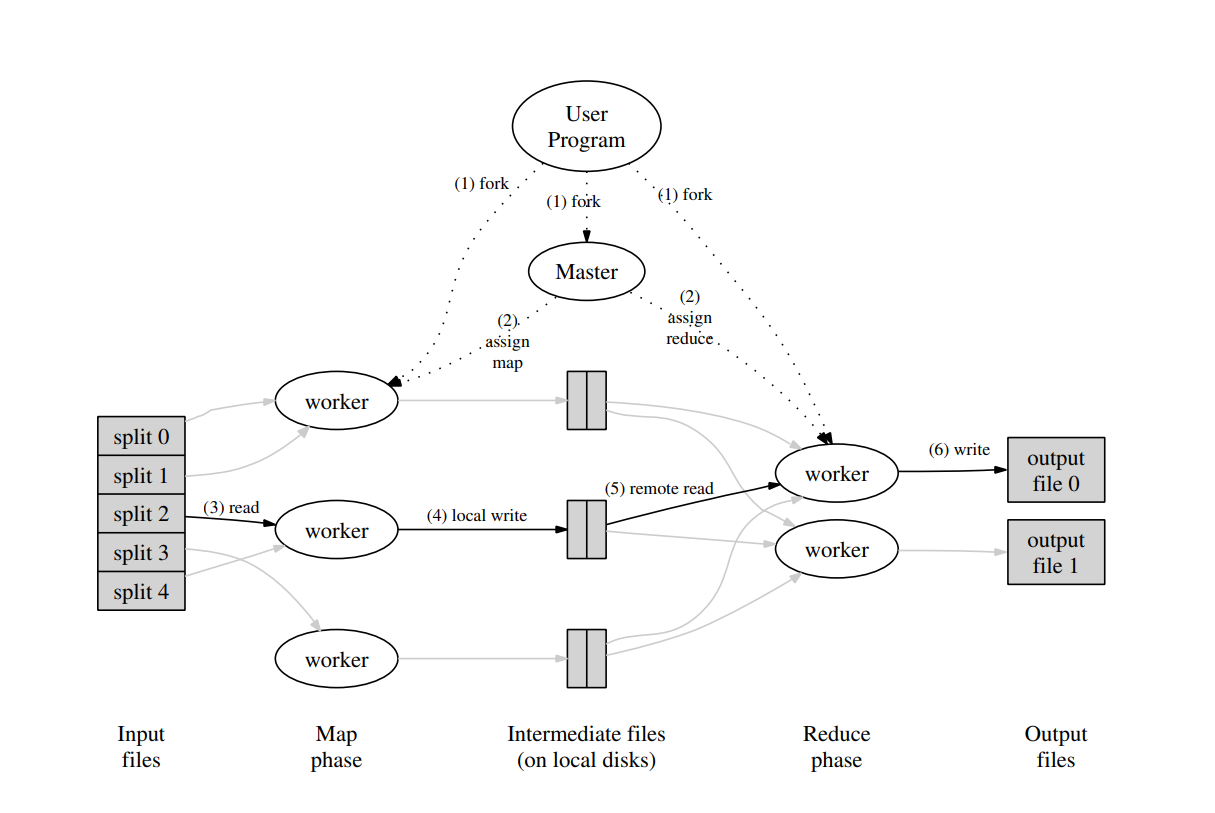
上图是mapreduce论文中对计算流程的介绍,很清晰,就不多赘述了
3. How to do it?
我们将目光拉回到LAB1上来,LAB相关的任务链接放在这里https://pdos.csail.mit.edu/6.824/labs/lab-mr.html
那么在这个LAB中我们要做什么呢?首先我们不需要完全从头开始完成这个框架,而是需要在LAB提供的代码中添加若干细节,使得不完整的map-reduce程序可以正常运行,下面简单介绍一下要求
- map阶段按照reduce任务数量
nReduce参数,每个reduce任务对应一个文件,这里需要我们在map阶段完成中间结果的分片 - 只能修改mr路径下的
coordinator.go,rpc.go,worker.go,并完成对应的实现 - 当任务全部完成时,worker需要主动退出,这块我们为了简化,可以认为当worker通过rpc调用coordinator失败时,就可以退出了
- 可以复制mrsequential.go 中的ihash和其他逻辑的代码
- 需要考虑worker失败的场景,如果一个worker失败,那么他只写了一部分的文件不能合并到总的接公众
我们先简单分析下代码的结构,下面只把部分有用到的代码列出来
1
2
3
4
5
6
7
8
9
10
11
12
├── main
│ ├── mrcoordinator.go //coordiantor 进程入口
│ ├── mrsequential.go //一个非分布式的wordcnt例子
│ ├── mrworker.go //worker 进程入口
│ ├── test-mr-many.sh //测试脚本
│ ├── test-mr.sh
├── models
│ └── kv.go
├── mr
│ ├── coordinator.go //coordinator server具体实现
│ ├── rpc.go //go rpc结构体定义
│ └── worker.go //worker 具体实现
其中,LAB要求我们完成coordinator,worker的具体实现,以及rpc调用
拆分,分析实现方式
由于任务要求已经比较清楚的将要做的事情拆分开了:实现coordinator,worker,那么我们从这一层开始分析
- coordinator需要做的事情
- 任务创建
- 根据输入文件和nReduce参数,创建任务,并且保存所有任务的信息
- 任务分发
- 当worker请求新任务的时候,任务打包返回给worker:这里我们使用一个队列实现,每次一次请求过来,就返回队头的任务
- 由于需要保证每个任务只执行一次,那么需要维护线程安全
- 任务状态的维护
- 维护每个任务的状态:运行,失败
- 需要维护任务的重试机制
- 任务创建
- worker需要做的事情
- 获取任务
- 执行任务
- 处理任务失败的情况
- 上报任务状态
接下来进入代码部分,只将项目的部分代码拿出来,完整版请到repo
拆分开任务之后,我们就可以根据这些要求,进行数据模型和具体处理任务分发的开发了 首先我们先补全coordinator,coordinator需要其他几个结构,也一并写好 ``` type Job struct { jobId string //任务的标识,方便调试 jobType string //任务类型:map,reduce,empty类型 partition int //分区id numReduce int //reduce分区数 input []string // 输入数据地址 output []string // 输出地址,长度应该是numReduce个 Status int //init 0,run 1,success 2,fail 3 } // jobSyncQueue 由于getJob是在go的协程环境下访问的,需要进行同步 type jobSyncQueue struct { lock sync.Mutex queue []*Job } // JobStatus 由于call done 同样是写成环境下,需要处理好数据同步问题 type JobStatus struct { lock sync.Mutex Status map[string]int //jobId:int Cnt map[string]int //jobId:failed cnt }
type Coordinator struct {
// Your definitions here.
workers map[string]int
jobInfo map[string]*Job
jobStatus JobStatus
jobQueue jobSyncQueue
}
1
第二个部分是rpc的结构,我们需要两个实现rpc func,分别于哦那个与worker获取任务,以及worker上报任务
type WorkerReq struct { WorkerId string }
type WorkerResp struct {
JobId string json:"jobId"
JobType string json:"jobType"
Partition int json:"partition"
NumReduce int json:"numReduce"
Input []string json:"input"
Output []string json:"output"
}
type WorkerReportReq struct { WorkerId string JobId string JobStatus int }
type WorkerReportResp struct { WorkerId string }
1
2
3
第三部分是比较重要的`Coordinator.Done`,这个方法需要遍历一次全部的任务,然后判断任务是否全部完成,如果有任务失败了,就需要重新将任务添加到队列里面
func (c *Coordinator) Done() bool { ret := true
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
// Your code here.
complete_job := 0
for jobId, item := range c.jobInfo {
// fmt.Printf("jobid %s status : %d is_finish %v \n", item.jobId, c.jobStatus.Status[item.jobId], is_job_finish)
curStatus := c.jobStatus.getStatus(jobId)
if curStatus == SUCCESS {
complete_job += 1
c.jobStatus.lock.Lock()
c.jobStatus.Status[jobId] = SUCCESS
c.jobStatus.lock.Unlock()
} else if curStatus == FAIL {
c.jobStatus.lock.Lock()
if c.jobStatus.Cnt[jobId] < 10 {
c.jobStatus.Cnt[jobId] += 1
c.jobStatus.lock.Unlock()
} else {
c.jobStatus.Status[item.jobId] = INIT
c.jobStatus.Cnt[item.jobId] = 0
c.jobStatus.lock.Unlock()
if item.jobType == "map" {
c.jobQueue.pushFront(item)
} else {
c.jobQueue.push(item)
}
log.Printf("Job failed after waiting for 10 s %s", jobId)
}
}
}
ret = complete_job == len(c.jobInfo)
log.Printf("Job status: %d/%d", complete_job, len(c.jobInfo))
return ret } ```
4. 总结
这次的lab实现MapReduce实际上对原理的一次深入理解,虽然通过了所有的测试点,但是还是有一些小瑕疵,欢迎大家直接在github上提issue